Nella serie di articoli sugli algoritmi, abbiamo affrontato il problema di come i pregiudizi umani si possono trasferire, involontariamente, alle macchine. Questo problema si inserisce in un contesto molto più ampio, quello della cosiddetta “etica delle macchine”, ovvero di come fare in modo che le macchine (siano esse robot, assistenti vocali, software di supporto alle decisioni, algoritmi per il riconoscimento delle immagini, servizi web) esibiscano dei comportamenti compatibili con i principi etici e morali della società in cui operano. Allo stesso tempo, molti esperti stanno mettendo in evidenza che, seppur fondamentale, il tema dell’etica delle macchine non è sufficiente a fornire strumenti efficaci per definire opportuni confini al raggio di azione dell’intelligenza artificiale. Questo aspetto è centrale per le società di oggi: siamo infatti in una fase di profonda trasformazione del lavoro, in cui l’intelligenza artificiale, la data science, e la potenza di calcolo delle odierne reti di calcolatori giocano un ruolo centrale. Le previsioni su come il lavoro si trasformerà sono molto contrastanti: si passa da chi indica un prossimo collasso del sistema del lavoro (immaginando un futuro prossimo in cui le macchine potranno sostituire l’uomo nella stragrande maggioranza dei compiti), a chi invece più cautamente dice che il lavoro non sparirà, ma si trasformerà creando nuove opportunità. Allo stesso tempo, gli esperti sono unanimi nel mettere in evidenza che c’è un nodo da sciogliere, nodo che potrebbe essere ancora più determinante dello sviluppo tecnologico nell’incidere sul futuro del lavoro: l’oligopolio nel mondo IT di pochissimi giganti, ovvero Facebook, Amazon, Apple, Microsoft, e Google. Questi giganti non possono essere controllati se ci si ferma al tema dell’etica: serve per questo un apparato di regole condivise. La regolamentazione in tal senso è stata, fino a pochi anni fa, praticamente assente. L’Europa, che spesso si trova a inseguire gli altri paesi nella corsa all’innovazione, è su questo tema assolutamente all’avanguardia, grazie alla recente introduzione del regolamento generale per la protezione dei dati (GDPR) ed alla prima proposta, a livello mondiale, per la definizione di un apparato normativo per l’intelligenza artificiale (Artificial Intelligence Act). Approfondiremo entrambi questi documenti nei prossimi numeri della nostra rubrica.
Nell’ultimo numero della “Città digitale” ci eravamo lasciati con questo intento: digitare nei traduttori online la coppia di frasi “Dorme e mangia con suo papà. Stira e mangia con suo papà”, per vedere come vengono tradotte in inglese. Il punto, come avrete immaginato, è capire il genere del soggetto: si tratta di un “lui”? O di una “lei”? Non lo sappiamo: il testo è ambiguo. Quello che si riscontra, però, usando questi software, è che in molti casi “decidono” di indicare in un “lui” (“he”) il soggetto della prima frase, e in una “lei” (“she”) il soggetto della seconda. Questo tipo di output è stato spesso commentato parlando dei preconcetti (in inglese, “bias”) degli algoritmi… come se gli algoritmi possano anche solo avere un intento discriminatorio. È su questo punto centrale che termina la nostra serie sugli algoritmi. Come è possibile che un algoritmo decida autonomamente che chi dorme è uomo, mentre chi stira è donna? La spiegazione è molto semplice, e viene, di nuovo, dai dati. Abbiamo già scritto che questi algoritmi di ultima generazione vengono “allenati” su una vastissima mole di dati, ed è su questa mole di dati che plasmano il proprio comportamento. Se in quei dati, statisticamente, quando si parla di “stirare” si trovano spesso soggetti femminili, l’algoritmo imparerà, implicitamente, a collegare questi due concetti. Non decide, semplicemente si adegua ai dati. La domanda seguente a questo punto è: perché si riscontra questa statistica nei dati? Perché è l’umanità stessa (o meglio, quell’umanità che produce dati per il mondo digitale) ad associare questi due concetti: i testi che parlano di “stirare” spesso si riferiscono a soggetti femminili, questi testi diventano dati per l’apprendimento degli algoritmi, e gli algoritmi ricostruiscono, indirettamente, gli stessi preconcetti (o distribuzioni statistiche che dir si voglia) presenti negli uomini e donne che quei dati li hanno generati. Non sta a noi qui dibattere sull’opportunità o meno di questo collegamento, né sul funzionamento di questi servizi di traduzione (anche se forse basterebbe, per sciogliere il nodo, che l’algoritmo chiedesse all’utente umano, invece di decidere autonomamente…). Ci preme semplicemente sensibilizzare i lettori su questo tema: a chi darete la “colpa” la prossima volta che vi troverete ad aver a che fare con un algoritmo che “non si comporta bene”?
Nello scorso numero abbiamo parlato di cosa sono gli algoritmi, soffermandoci su un aspetto centrale: un algoritmo segue una sequenza di passi di calcolo ben definiti e, a parità di ingresso, l’algoritmo produrrà sempre lo stesso risultato. Questa caratteristica viene meno in quegli algoritmi che vengono utilizzati in intelligenza artificiale per “imparare” a riprodurre un certo comportamento, e capire questa differenza è centrale per capire poi perché questa nuova generazione di algoritmi si comporta talvolta in modo sorprendente, talvolta fallendo miseramente. Prendiamo il caso di tradurre una frase dall’italiano all’inglese. Definire un algoritmo che sia in grado di effettuare la traduzione per una qualunque frase italiana di senso compiuto sembra un compito irrealizzabile se seguiamo la definizione classica di algoritmo. Tantissimi ricercatori, sia in campo accademico che industriale, stanno affrontando queste problematiche. Tra questi, una corrente propone di risolvere il problema nel modo seguente. Si prende “algoritmo di apprendimento” capace di riconfigurare internamente il proprio comportamento (ad esempio, modificando una serie di configurazioni interne in modo da cambiare che risultato verrà prodotto dato un certo input). In particolare si usano allo scopo algoritmi di apprendimento “supervisionato”, a testimoniare che l’algoritmo impara come se avesse un docente. Cosa fa il docente? In realtà non insegna nulla: fornisce semplicemente una lunghissima serie di esempi di frasi italiane tradotte in modo soddisfacente in inglese. Dopo essersi allenati su milioni e milioni di frasi tradotte, questi algoritmi di ultima generazione mostrano di saper tradurre anche su esempi nuovi, mai visti. E più vengono allenati, più sembrano diventare bravi. Ma come sempre, c’è sempre un ma… dov’è finita la “chiara sequenza di passi” degli algoritmi classici? E quanto l’algoritmo dipende dai dati? Vi lascio con una richiesta. Provate a scrivere queste due frasi in diversi traduttori online, e controllate cosa viene prodotto nella traduzione: “Dorme e mangia con suo papà. Stira e mangia con suo papà”.
Iniziamo la nostra miniserie di incontri con gli “algorimi”, che abbiamo introdotto nello scorso numero del giornale, tornando all’esempio dei trasferimenti dei docenti anche molto lontanato da casa. Il Tar del Lazio si è pronunciato sull’evento, accaduto ormai 5 anni fa, dicendo che “l’algoritmo impazzito fu contro la Costituzione” (Repubblica, 17/09/2019). Cerchiamo quindi innanzitutto di capire cosa sia effettivamente un algoritmo. L’etimologia della parola ci arriva dal nome del matematico arabo al-Khwarizmi, vissuto nell’VIII secolo d.C. A lui si deve la definizione di metodi per risolvere equazioni, descritti con sequenze di istruzioni semplici che, se eseguite alla lettera passo per passo, prendono in ingresso un’equazione e producono in uscita la soluzione. Questa idea di una “chiara sequenza di istruzioni per trasformare un input in un output” è alla base del concetto stesso di algoritmo così come lo intendiamo ancora oggi, e mostra un chiaro collegamento tra matematica e informatica: se abbiamo una chiara sequenza di istruzioni, possiamo “codificarla” in un opportuno linguaggio di programmazione e farla così eseguire al calcolatore.
Se un algoritmo non è quindi altro che un “procedimento sistematico di calcolo, oggi per lo più destinato a essere eseguito da un automa esecutore quale un computer” (treccani.it), come è possibile anche solo pensare che un algoritmo possa impazzire? La risposta è semplice: gli algoritmi non impazziscono. L’algoritmo di allocazione dei docenti ai posti disponibili è “impazzito” perché, in effetti, non è stato definito correttamente, ed è stato applicato su dati dei docenti incompleti o addirittura incorretti. Ovviamente un algoritmo definito impropriamente e chiamato a produrre un risultato su dati sbagliati non può che dare risultati insoddisfacenti. Portiamo quindi a casa un primo, chiaro messaggio: invece di parlare della “pazzia degli algoritmi”, dovremmo forse concentrarci sula “(in)competenza delle persone”.
Si sente sempre più spesso parlare degli algoritmi come fossero vere e proprie “intelligenze artificiali”, capaci di decidere i nostri destini in modo opaco e distopico. Di esempi concreti ce ne sono a bizzeffe. Molti di voi ricorderanno il caso di qualche anno fa dell’algoritmo utilizzato per allocare i docenti alle scuole sul territorio nazionale, e che in vari casi ha portato persone a doversi spostare di centinaia di km. Per non parlare degli algoritmi che, proprio in questi giorni, portano a colorare le diverse regioni e provincie d’Italia in base all’andamento della pandemia di COVID-19.
Il problema è in realtà molto più ampio. La nostra storia recente abbonda di situazioni in cui gli algoritmi hanno “mostrato comportamenti scorretti o poco etici”: algoritmi di riconoscimento facciale che confondono persone e gorilla, algoritmi per decidere sui prestiti bancari che “preferiscono” gli uomini alle donne, algoritmi per l’analisi dei carcerati che indicano genericamente le persone di colore come più tendenti a recidivare nei propri crimini.
In tutti questi esempi, torna di nuovo un riferirsi agli algoritmi come esseri senzienti, dotati di “preferenze”, “potere decisionale” e, non per ultimi, “preconcetti”. Cercheremo, nei prossimi numeri della nostra rubrica, di fare un’opera di chiarezza su questi fantomatici algoritmi, cercando di ristabilire un po’ di ordine e di sano equilibrio. Lo faremo utilizzando esempi concreti, con un triplice scopo. In primis, ricorderemo da dove proviene il termine “algoritmo”, e cosa sia davvero un algoritmo. In secondo luogo, distingueremo tra gli algoritmi che vengono utilizzati per risolvere problemi, e quelli che vengono utilizzati per imparare dai dati. Da ultimo, ci soffermeremo, come già molte volte abbiamo fatto, sulla natura di questi dati: chi li ha prodotti, chi li consegna agli algoritmi. Con un tema di fondo sempre presente: quello della responsabilità e dell’importanza di responsabilizzarsi.
Ho pensato a lungo a come avrei voluto concludere la rubrica della “città digitale” in questo 2020 così difficile sotto tanti punti di vista. Avrei certamente potuto raccontarvi di qualche curiosità o ulteriore avanzamento della tecnologia, che sempre più sta diventando un’estensione di noi stessi – come un grande paio di occhiali sul mondo, digitale e non. Oppure avrei potuto raccontarvi di una delle tante problematiche che ancora le nostre città non hanno risolto. Ma sono tutti esempi piccoli di fronte ad un tema molto più ampio che ci tocca, e ci deve sempre più toccare, tutti: quello dell’alleanza, ancora purtroppo incompiuta, tra scienza e umanesimo. In quest’anno di pandemia ci siamo accorti ancora una volta di quanto non sia fatta di certezze, ma di evidenze da scoprire con fatica e dedizione, di passi falsi e dibattiti, di torri che vengono costruite piano piano, buttate giù, e ricostruite. Ce ne siamo accorti quando abbiamo sentito gli scienziati in disaccordo su molti dei temi di dibattito: questa è la normalità, sopratutto se consideriamo che il Covid-19 è un fenomeno davvero molto recente. Ma ci siamo anche accorti che spesso i messaggi degli scienziati sono indecifrabili, e quando non si capisce ci si arrabbia, e arrabbiandosi si arriva persino al rigetto (e quindi alla negazione) della realtà. Chi, se non gli umanisti (nell’accezione più ampia del termine), possono aiutare gli scienziati a farsi comprendere meglio? Migliorare la comunicazione di concetti difficili è però solo una piccolissima parte del problema. Abbiamo visto ancora una volta quanto la scienza, l’economia, la politica, l’etica, e chi ne ha più ne metta, non possono essere considerate a compartimenti stagni: creano una matassa che possiamo districare solo creando una vera e propria alleanza virtuosa tra tutte queste discipline. Un’alleanza in cui i medici si confrontano con filosofi e sociologi prima di parlare al grande pubblico, in cui l’etica viene affiancata all’economia, in cui i dati vengono curati dagli esperti informatici e presentati da designer ed esperti di comunicazione, in cui sono i pedagogisti a indicare come trasformare la didattica e le aule. Tornando, nel nostro piccolo, alla città digitale, mai come oggi è importante tornare a leggere il Manifesto di Vienna sull’umanesimo digitale (https://dighum.ec.tuwien.ac.at/dighum-manifesto/). Se non ora, quando?
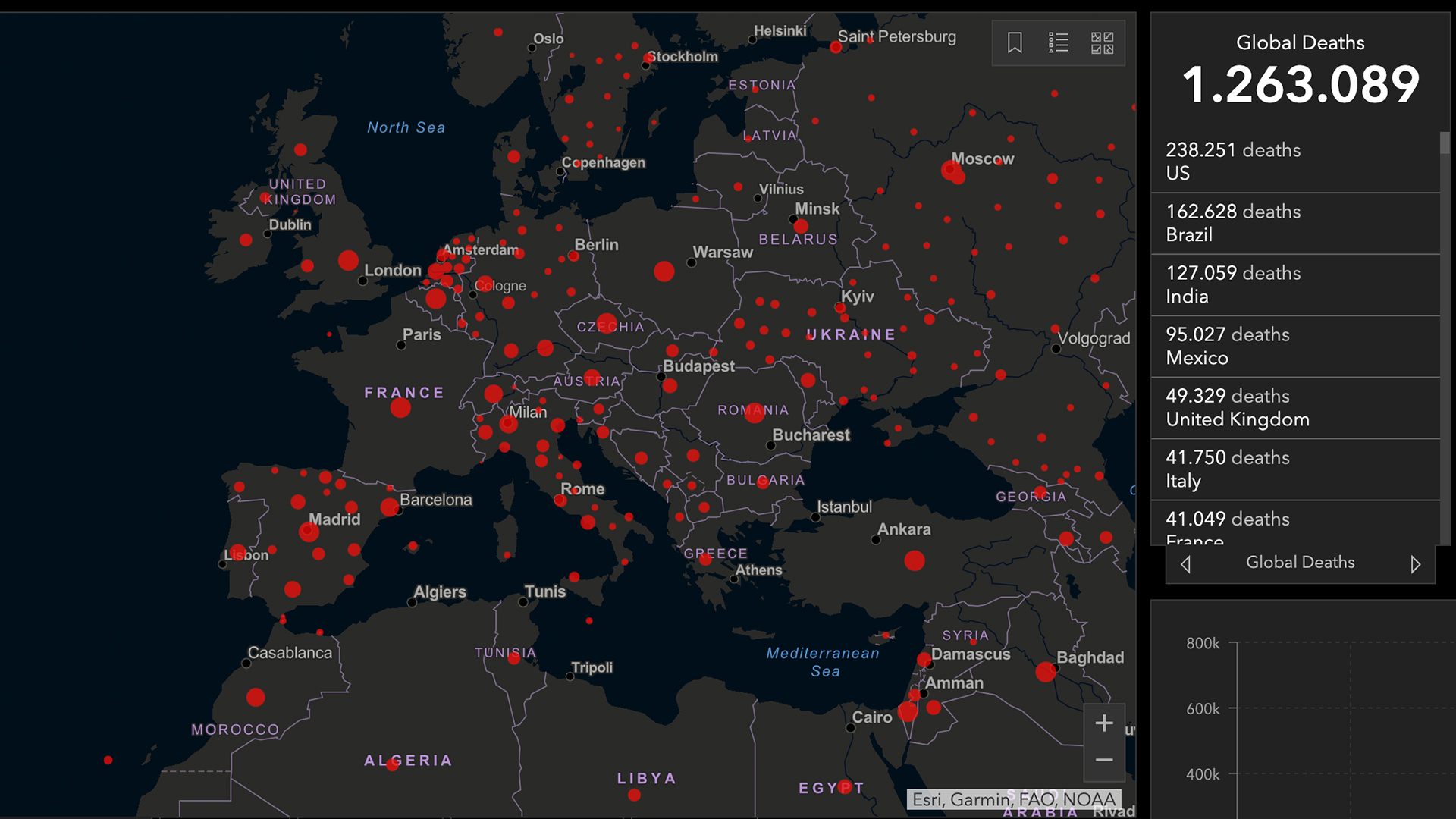
La recente, seconda ondata pandemica che sta travolgendo l’Italia in questi giorni sta nuovamente portando alla luce quanto i dati stiano diventando sempre più importanti per prendere decisioni strategiche. Senza i dati siamo letteralmente ciechi, con i dati possiamo capire cosa sta succedendo. Non stupisce quindi che l’analisi del rischio di tracollo dei sistemi sanitari locali sia basata, ad oggi, sull’analisi dell’andamento di tutta una serie di dati fondamentali, come la velocità di trasmissione del contagio, il numero di posti occupati in terapia intensiva, e così via. Il problema è che questi dati vanno raccolti, raffinati, messi assieme, aggregati, trasformati. Come nelle ricette di pasticceria, ognuno di questi passaggi va effettuato con grande cura, attenzione e precisione: un singolo errore può pregiudicare il risultato finale. Altrettanto importante è assicurarsi la qualità della materia prima: dati grezzi che non rappresentano fedelmente la realtà porteranno, alla fine della catena, a prendere decisioni sbagliate. Per i tecnici informatici che si occupano di gestire e analizzare i dati, questo fenomeno è noto con il temine “spazzatura in ingresso, spazzatura in uscita”. Si tratta di un tema apparentemente banale, che però viene fin troppo spesso dimenticato: si parla sempre della “quantità” dei dati (i famosi “big data”), senza enfatizzare l’importanza della “qualità” dei dati. Le cronache recenti sul Covid-19 in Italia stanno, in modo drammatico, portando alla luce proprio questo tema: si parla di “dati che arrivano in ritardo”, di “buchi nei dati”, di “difficoltà nel comunicare i dati”, e così via. Ma come mai è così difficile “muovere” questi dati in modo corretto, in una società che ha a disposizione le più moderne e sofisticate tecnologie per la memorizzazione e l’integrazione dei dati? La risposta sta nel fatto che siamo sempre di più “in rete”, ma ancora non in grado di “fare rete”. E questa incapacità di coordinarsi collettivamente si trasporta purtroppo nei nostri sistemi informatici: invece di avere pochi sistemi capaci di scambiarsi direttamente dati “parlando la stessa lingua”, ci troviamo con migliaia di software diversi, isolati l’uno dall’altro, e che raccolgono dati con formati molto diversi. In questo contesto, ogni trasferimento da un sistema all’altro richiede che altri software, o l’uomo stesso, facciano da “traduttori”, con tutti i ritardi e gli errori che ne conseguono. Le tecnologie per risolvere questi problemi ci sono, sta a noi rimboccarci le maniche e smontare pezzo per pezzo questa torre di Babele.
La città digitale è sempre più intimamente connessa all’Intelligenza Artificiale (IA). Algoritmi e tecniche di IA sono impiegati ormai dappertutto: nei nostri cellulari, nelle nostre automobili, nei software gestionali utilizzati dalle aziende, e così via. Da un punto di vista scientifico l’IA è una disciplina, nata ormai 60 anni fa, il cui scopo ultimo è rendere i calcolatori capaci di manifestare comportamenti “intelligenti”. Nell’ambito dell’IA sono state sviluppate tecnologie informatiche avanzate quali il processamento del linguaggio naturale, la visione artificiale, la robotica, la rappresentazione della conoscenza, il ragionamento automatico, la pianificazione, e l’apprendimento automatico (o machine learning). Nell’ultimo decennio l’IA ha subito un incredibile rilancio, che l’ha portata dall’essere una disciplina di nicchia e futuristica a una che tocca ormai tutti i settori della nostra società. Tale sviluppo è stato reso possibile da una parte dall’aumento della potenza di calcolo e di memorizzazione dei calcolatori odierni, e dall’altra parte dallo sviluppo di nuovi metodi matematici e statistici nell’ambito del machine learning. Ne derivano interrogativi fondamentali riguardo all’impatto dirompente di tali tecnologie, alle loro implicazioni etiche e sociali, e all’opportunità di favorire uno sviluppo indiscriminato dell’IA. Di questo tema si parlerà in una serie di tre incontri, resi possibili grazie all’iniziativa di Luigi Cirimele e Gianfranco Amati e all’organizzazione congiunta di UPAD Merano in collaborazione con l’Accademia di studi italo-tedeschi. I primi due incontri daranno una panoramica storica dell’IA, ne approfondiranno le principali tecniche e applicazioni, e ne discuteranno l’impatto sociale. Saranno tenuti dal Prof. Diego Calvanese e dal sottoscritto. Nel terzo incontro il Dott. Mattia Merlini si concentrerà sul tema della creatività computazionale. Per chi è interessato, il luogo è Villa San Marco a Merano, e le date sono il 12/10/2020, il 26/10/2020, e il 9/11/2020, dalle 18.30 alle 20. L’ingresso sarà libero ma, considerando le misure di distanziamento sociale, la capienza sarà limitata.
Gli algoritmi per il riconoscimento delle immagini stanno diventando sempre più diffusi e importanti. Sono già ad oggi impiegati, in modo più o meno visibile, in una ampissima gamma di applicazioni. Basti pensare alle app per la memorizzazione e la ricerca di foto, capaci di raggruppare tutte le foto in cui compare la stessa persona, o a sistemi molto più complessi come quelli che alcuni paesi stanno impiegando per tracciare movimenti e comportamenti dei propri cittadini. Evitando queste derive distopiche, ho recentemente riscoperto l’utilità di questi algoritmi mentre stavamo camminando nei campi e mia figlia mi ha chiesto se i frutti di un albero che non avevo mai visto prima fossero commestibili. In quell’occasione ho potuto utilizzare una delle numerosissime app che si possono scaricare sui nostri cellulari gratuitamente (o per pochi euro): ho fatto una foto all’albero e in una manciata di secondi l’app mi ha dato tutte le informazioni di cui avevo bisogno (nome, habitat, e così via). Come abbiamo già raccontato in passato, la caratteristica di questi algoritmi è quella di saper “imparare”: vengono addestrati con numerosissime immagini già classificate (ad esempio, immagini di melo, pero, albicocco), e imparano senza alcun intervento esterno a mimare i meccanismi che hanno portato a quella classificazione. Il risultato è spesso stupefacente per precisione, talmente stupefacente che l’app che ho utilizzato ha riconosciuto l’albero che ho fotografato riuscendo ad eliminare tutte le sorgenti di disturbo (presenza di altri alberi, cielo, oggetti vari). Come sempre, c’è però l’altra faccia della medaglia. Se è vero che questi algoritmi sono precisissimi nell’apprendere, è altrettanto vero che possono molto facilmente essere “fuorviati”. Già nel 2016, un team di ricercatori esperti di sistemi biometrici ha mostrato come indossando occhiali con particolari motivi e colori, fosse possibile prendersi gioco di alcuni noti algoritmi di riconoscimento facciale, facendosi classificare come divi di Hollywood. Potete solo immaginare quante multe prenderebbe George Clooney se questi algoritmi venissero impiegati per multare automaticamente chi è in eccesso di velocità.
Uno dei temi che sempre ricorrono in questa rubrica è quello dei dati. Nella città digitale i dati sono fondamentali per produrre servizi di qualità. Quando si parla di dati, spesso ci si riferisce al fatto che sono tantissimi, conseguentemente enfatizzando il fatto che per gestire questi “big data” abbiamo bisogno di un’enorme potenza “muscolare”. In realtà, la gestione dei dati è un tema molto più complesso. Una delle dimensioni fondamentali è quella della “qualità” del dato: se i dati che vengono raccolti sono interpretati male, troppo incompleti o non fedeli ai corrispondenti fenomeni reali, i servizi ai cittadini che vengono realizzati sulla base di questi dati diventano inutili, se non dannosi. Per costruire una casa solida servono, dunque, solide fondamenta. Un modo molto semplice per cercare di avere dati di qualità è quello di raccoglierli quanto più possibile vicino alla fonte, con dei meccanismi per cui chi sta alla fonte abbia interesse a essere quanto più possibile preciso e completo nel tradurre la propria realtà in dato.
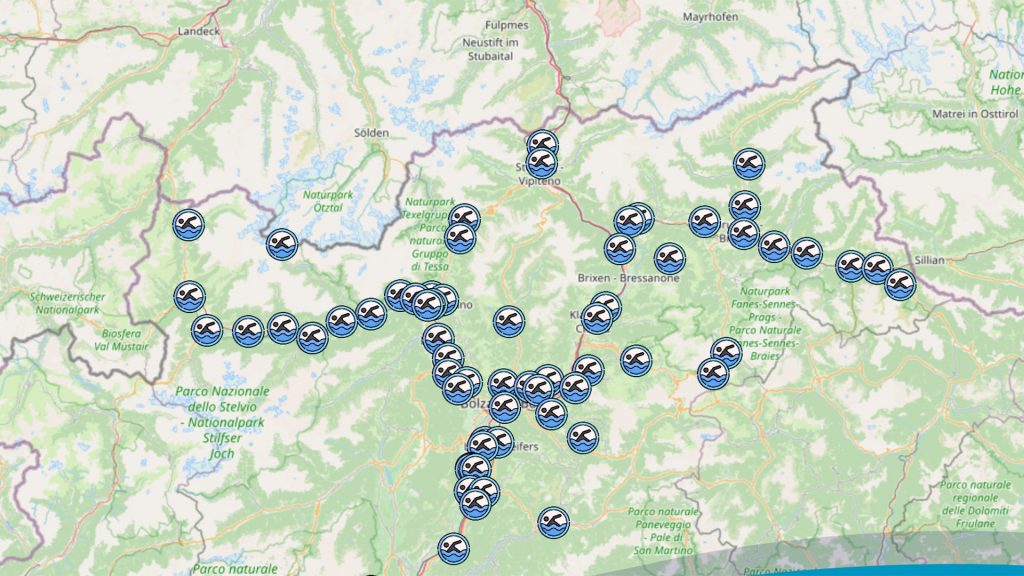
Un esempio molto calzante è quello di lidonews.it. Si tratta di un sito che censisce tutti i lidi dell’Alto Adige, fornendo indicazioni su quali lidi sono aperti, e quali lidi hanno ancora posti disponibili – tema particolarmente importante in questa complessa fase di distanziamento sociale. Il sito funziona con un meccanismo molto semplice: sono i gestori stessi dei lidi a indicare, in tempo reale e tramite una app dedicata, quanti posti disponibili ci sono. Lidonews si occupa a quel punto di aggregare tutte queste informazioni in un unico portale, dando anche indicazioni chiare su quando è stato effettuato l’ultimo aggiornamento dei posti disponibili, lido per lido. Un servizio semplice ma davvero efficace.