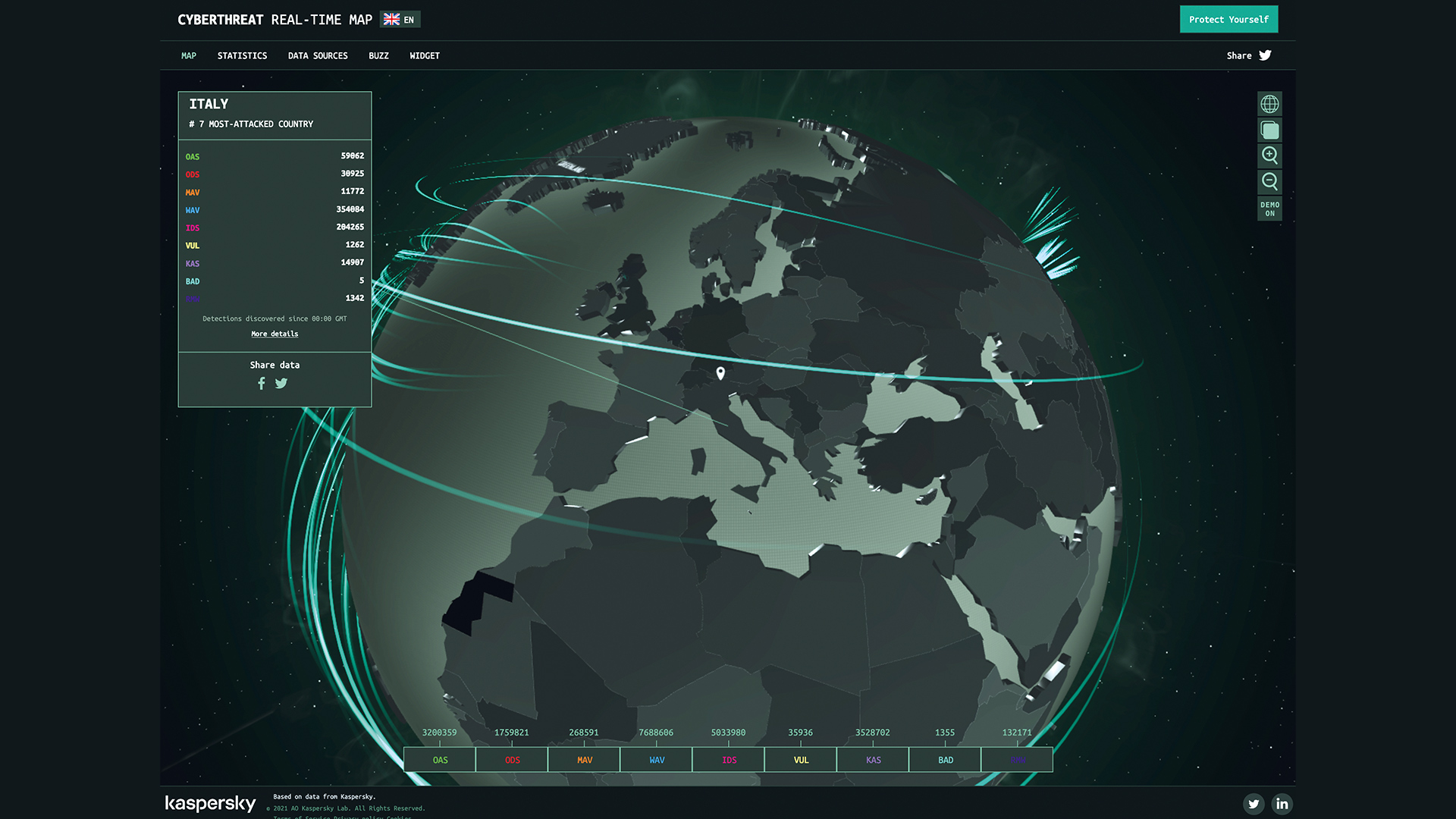
Molto si è scritto su come la guerra in Ucraina (e tutte le guerre dei nostri giorni) si combatta in effetti a vari livelli, incluso quello informatico. Cerchiamo di capire un po’ meglio di cosa si tratta. Innanzitutto, è importante evidenziare che gli attacchi compiuti tramite internet alle infrastrutture informatiche di una terza parte (un privato cittadino, un’azienda, un ente governativo), ovvero i cosiddetti “cyberattacchi”, avvengono incessantemente in tutto il mondo a ritmi sempre più frenetici. Per farsi un’idea dell’entità del problema, si possono consultare su internet mappe che mostrano gli attacchi che stanno avvenendo nel mondo. Basta digitare su un motore di ricerca “cyber threat maps”, per trovare mappe come quella di Checkpoint (https://threatmap.checkpoint.com) e Kasperksi (https://cybermap.kaspersky.com), entrambe aziende molto note nel settore della sicurezza informatica, con Kasperski attualmente sotto il mirino delle autorità di cybersecurity per presunti collegamenti col governo russo. Ora che ci siamo fatti un’idea dell’enorme entità del problema, cerchiamo di capire quali sono gli attacchi informatici rilevanti in un contesto bellico. Una prima grande famiglia di attacchi è quella legata a infrastrutture e apparecchiature critiche, come sistemi militari, commerciali, energetici, e delle telecomunicazioni. Questo tipo di attacco può al giorno d’oggi interrompere o intralciare l’erogazione di servizi utilizzati dal nemico in tantissimi settori diversi, considerando che sempre più sistemi sono controllati attraverso software connessi in rete (si pensi che, quando qualche mese fa Facebook ha smesso di funzionare per qualche ora, alcuni dipendenti dell’azienda non sono stati fisicamente in grado di entrare nei propri uffici). Un’altra tipologia di attacco mira alla raccolta di dati sensibili, dall’intercettazione di informazioni utili per capire come si stanno muovendo le truppe, fino alla pubblicazione di dati privati come indirizzi e contatti telefonici del personale militare. Spesso gli attacchi non hanno un vero e proprio fine strategico, quanto più un intento “muscolare”: mostrare la propria capacità di infiltrare i sistemi informatici del nemico e vandalizzarli. Si parla infine di attacchi non specificatamente orientati a colpire i militari, quanto a influenzare l’opinione pubblica, con attacchi su larga scala volti a comunicare con il grande pubblico a fini informativi, propagandistici, o di guerra psicologica. Tutto questo conferma, ancora una volta, come il mondo fisico e digitale siano sempre più intimamente connessi.
Marco Montali
Autore: Marco Montali

Interrompiamo la serie di articoli sulla didattica a distanza per riflettere su alcuni temi centrali di grande attualità, soprattutto in considerazione degli eventi drammatici di questi giorni.
Nella nostra rubrica abbiamo sempre, implicitamente o esplicitamente, parlato dei dati come condizione necessaria e motore per la realizzazione di servizi nella città digitale. Parlare di dati evoca immediatamente aggettivi e connotazioni legate all’enorme quantità degli stessi, e alle corrispondenti difficoltà tecniche e umane per immagazzinarli, processarli, comprenderli. Immagino tutti voi abbiate sentito, almeno una volta nella vostra vita, il termine “big data”, a enfatizzare appunto l’enorme “volume” dei dati con cui abbiamo a che fare quotidianamente.
È importante ricordare che il “volume” rappresenta solo una delle cosiddette “quattro V” dei big data. Scopriamo le altre tre.
Innanzitutto, c’è la “velocità”: enormi quantità di nuovi dati vengono prodotte in ogni minuto della nostra vita. Secondo l’infografica “Data Never Sleeps 9.0” di Domo, facilmente reperibile sul web, in un minuto accadono fenomeni come 167 milioni di video visti su TikTok, 6 milioni di acquisti online, 856 minuti di incontri contemporanei su Zoom, 452000 ore di film e serie visualizzati su Netflix.
C’è poi la “varietà”: abbiamo dati rappresentati in forma strutturata (come tabelle e record nei database), semi-strutturata (come report e grafici), o non strutturata (come immagini, video, registrazioni vocali, testo libero).
C’è infine la “veridicità”: spesso non sappiamo se i dati che raccogliamo sulla realtà rappresentano davvero una descrizione accurata e fedele della realtà stessa. Pensate ai ben noti fenomeni delle fake news o di immagini e video artefatti, ma anche al fatto che spesso i dati non raccontano fatti, bensì opinioni.
Queste “quattro V” si ritrovano in tutta la loro problematicità nei dati, drammatici, che costantemente ci arrivano dalla guerra in Ucraina: tantissimi dati, in continua evoluzione, di vario tipo, e spesso difficilmente verificabili. Un esempio, diretto e forte, in questo senso è reperibile al sito https://maphub.net/Cen4infoRes/russian-ukraine-monitor, che mostra sulla mappa dell’Ucraina e dintorni una varietà di dati pescati automaticamente dai social network, sfruttando il fatto che foto, video, e testi vengono sempre implicitamente associati al “dove” e “quando”, registrando la località e il momento in cui sono stati caricati. Un esempio che mostra in fondo una “quinta V”: il “valore” implicitamente presente in questi dati, e la difficoltà e responsabilità che dobbiamo mettere in campo per poter effettivamente trasformare i dati in valore.
Autore: Marco Montali

La didattica a distanza (nota ormai comunemente con l’acronimo DAD) ha recentemente inondato la nostra società, entrando nelle case di milioni di bambini e ragazzi. In questa serie di articoli, che inauguriamo oggi, cercheremo di approfondire alcuni aspetti, tecnologici e non, legati alla DAD. Non avremo alcuna pretesa di completezza, trattandosi di un tema con radici molto profonde, e che coinvolge non solo tecnologia, ma anche e soprattutto pedagogia, gestione dei gruppi, insomma il “fattore umano”. Piuttosto cercheremo di aprire qualche finestra su questo tema complesso e mai così attuale. Oggi ci occupiamo delle tecnologie di base per l’erogazione di didattica a distanza. Il primo aspetto da enfatizzare è la necessità di disporre di una connessione a internet. Questo aspetto può sembrare davvero banale, ma non lo è, se consideriamo che da recenti statistiche il 6% delle famiglie non ha potuto usufruire della DAD proprio a cause di carenze nell’infrastruttura di rete.
Su questa base essenziale, la DAD erogata in tempo reale avviene catturando l’audio e il video del docente, mediante l’equipaggiamento audio-video presente ormai in ogni computer, tablet, o cellulare, oppure utilizzando hardware più avanzato (in termini di videocamera e microfono). I dispositivi degli alunni si collegano alla lezione attraverso software dedicati che giocano il duplice ruolo di piattaforme di condivisione (per permettere a più partecipanti di essere presenti in una vera e propria “aula virtuale”) e di streaming (per inviare l’audio e il video ai partecipanti). Alcuni software di base per realizzare questo servizio sono gli ormai famosi Zoom, Teams, e Meet. Offrono tutti simili funzionalità: oltre alla possibilità di seguire la lezione, quella di intervenire (via messaggio o con il proprio audio e video) con meccanismi di gestione del turno che cercano di ricalcare quelle delle aule virtuali (vedi la classica “alzata di mano”), di condividere una presentazione preparata al computer o lo schermo, di attivare lavagne virtuali e collaborative, e così via. Spesso questi software vengono utilizzati o assieme ad altri programmi (come ad esempio “Mentimeter”, per inviare questionari in tempo reale, raccogliere le risposte e visualizzare statistiche), o nel contesto di più ampie piattaforme per la gestione delle classi. Un esempio in tal senso è Meet di Google, spesso utilizzato all’interno di Google Classroom, che supporta l’erogazione di materiale didattico, la consegna dei compiti, e così via. Non abbiamo fin qui però parlato di due aspetti fondamentali. Da un lato il fatto che la DAD apre opportunità e sfide che vanno molto al di là della erogazione di didattica a distanza in tempo reale. Dall’altro lato il fattore umano, pedagogico e di gestione dei gruppi, per far sì che lo strumento tecnologico si trasformi in un vero e proprio servizio. Ne parleremo nei prossimi numeri della nostra rubrica.
Autore: Marco Montali

Sono passati ormai più di 5 anni da quando il filosofo Luciano Floridi ha coniato il termine “onlife”, a significare che la nostra vita si svolge ormai in un continuo coesistere tra la dimensione fisica (offline) e quella digitale (online). Nelle nostre città siamo in effetti sempre più “onlife”. Un interessante esempio di questa commistione è l’utilizzo del web, dei dispositivi cellulari, e di tecnologie che permettono di fornire informazioni e servizi agli utenti in base al luogo esatto in cui si trovano, e agli oggetti che li circondano. La più semplice tecnologia di questi “servizi localizzati” è quella, di cui abbiamo già parlato, del QR Code: un codice a barre a due dimensioni, ormai noto a tutti per la dibattuta questione del greenpass. Basta posizionare un apposito QR Code in un punto preciso della città, assicurandosi che, una volta letto, rimandi a una pagina web appositamente sviluppata (o sia interpretabile in modo corretto da una app presente sul cellulare), e il gioco è fatto. Un esempio di questo approccio è “Di Verso Inverso”, il “percorso di realtà aumentata” dedicato a Dante nell’occasione dei 700 anni dalla sua morte. Nove installazioni, distribuite nelle città di Bolzano, Merano, e Bressanone, possono essere fruite nella loro dimensione fisica e, allo stesso tempo, rimandano a contenuti digitali accessibili inquadrando QR code posti su esse. Per poter fruire dei contenuti digitali, basta scaricare la app gratuita imaginAR e seguire le istruzioni. La presenza di QR Code richiede un approccio attivo da parte delle persone: sono loro a decidere se inquadrare o meno il codice, e fruire dei corrispondenti contenuti digitali.
Diverso è il caso dei beacon, veri e propri “fari digitali” bluetooth che, posizionati nelle città in precisi punti, interagiscono autonomamente con i dispositivi cellulari, scatenando (previo consenso) azioni specifiche che vengono eseguite dai cellulari stessi, tipicamente sfruttando il web per ottenere ulteriori informazioni. Le applicazioni sono davvero tantissime: si va dall’inviare automaticamente a un turista informazioni sui punti di interesse della città che incontra camminando, a inviare pubblicità su sconti e offerte quando si passa davanti ad un negozio. Beacon Südtirol-Alto Adige, un progetto finanziato dal fondo sociale europeo e svolto tra il 2018 e il 2020, ha creato un’infrastruttura di beacon molto capillare su tutto il territorio altoatesino. Tra le applicazioni che sono state realizzate su questa infrastruttura c’è quella che traccia la posizione esatta dei bus nelle città di Bolzano e Merano, grazie appunto alla presenza di beacon posti alle fermate e sui bus stessi. Maggiori informazioni sono disponibili al sito beacon.bz.it
Autore: Marco Montali

(continua)
Oggi continuiamo a parlare dell’apprendimento per rinforzo in intelligenza artificiale, in particolare per evidenziare il problema dell’allineamento dei valori tra uomini e macchine. Richiamiamo l’idea dell’apprendimento per rinforzo, di cui abbiamo parlato nello scorso numero: si tratta di fornire alla macchina la capacità di acquisire informazioni sullo stato corrente del mondo, di effettuare un’azione tra le varie disponibili, e di ottenere di un’indicazione numerica su quanto la scelta sia da premiare (o punire). Quest’ultimo aspetto, che dev’essere deciso dall’esperto umano che programma la macchina, è centrale: più azioni vengono fatte, più la macchina utilizza i premi ricevuti per ottimizzare sempre di più sulle scelte fatte, cercando di accumulare il premio totale più alto possibile. Quest’idea è stata ampiamente utilizzata nel contesto dei giochi: è alla base, ad esempio, di alphaGo, il software di google che nel 2015 è stato capace di sconfiggere il campione mondiale di Go (un gioco di strategia che presenta un numero di configurazioni enormemente più elevato degli scacchi, e che non si pensava potesse essere assolutamente alla portata dei computer). Ma cosa c’entra in tutto questo “l’allineamento dei valori”? C’entra perché non sempre quello che l’uomo vuole che la macchina impari coincide davvero con quello che la macchina imparerà davvero: non dimentichiamoci infatti che la macchina non sa davvero cosa voglia l’uomo: semplicemente usa i premi numerici ricevuti per ottimizzare le proprie decisioni. Tra i tanti esempi che ci mostrano quanto sia facile rompere questo allineamento, ne ho scelti due. Il primo: per insegnare a un robot cuoco che per cucinare i pancake bisogna evitare di tenerli troppo in padella, gli viene indicato un premio che è tanto maggiore quanto il pancake sta in aria. Invece di imparare a far saltare spesso il pancake in padella, il robot impara a fare un unico, lancio altissimo. Il secondo: per insegnare a un programma a giocare a un videogioco in modo esplorativo, l’esperto umano lo imposta indicando che qualunque azione faccia non restituirà nessun premio, tranne nel caso in cui l’azione porti al “game over” – in quel caso, il programma riceverà una punizione. Il programma così impostato impara, inaspettatamente, a mettere subito il gioco in pausa: in questo modo, non si raggiungerà mai il “game over”. Sono esempi curiosi, che ci insegnano però quanto è ancora lunga la strada nello sviluppo dell’intelligenza artificiale.
Autore: Marco Montali

L’intelligenza artificiale sta diventando sempre più presente nelle nostre vita e nelle nostre città. Uno dei grandi problemi aperti in intelligenza artificiale è quello del cosiddetto “allineamento dei valori”: come facciamo a essere certi che queste macchine si comportino secondo le norme e le regole di comportamento vigenti, nonché rispettando i princìpi etici e i valori umani? Un elemento specifico in questo contesto è la condivisione dell’obiettivo da raggiungere. Lo trattiamo per raccontarvi quanto ancora siamo lontani da questa condivisione. Immaginate questi esempi: come facciamo a comunicare a un veicolo autonomo quale è il suo “obiettivo primario”? E a un programma che deve mostrare abilità nel giocare ad un videogame? E ad un robot che deve afferrare una palla?
Una branca dell’intelligenza artificiale, chiamata “apprendimento per rinforzo”, ha proposto una visione radicale e molto generale per costruire macchine in grado di risolvere problemi così diversi. L’idea è molto semplice… alla macchina non viene insegnato nulla, se non tre funzioni fondamentali. La prima è la capacità di “prendere in input” un’informazione sullo stato corrente del mondo. Ad esempio: l’immagine fotografica attuale catturata da una videocamera posta sul cruscotto del veicolo o sul braccio del robot, o la configurazione dei pixel dello schermo che mostra il videogioco che si sta giocando. La seconda funzionalità è la capacità di “agire” nel mondo, senza sapere, inizialmente, quale sarà l’effetto delle proprie azioni. Ad esempio: frenare/accelerare l’auto; aprire o chiudere la mano robotica, o girare il braccio; muovere il personaggio del videogioco avanti o indietro; e così via. La terza funzionalità è quella di ottenere, una volta effettuata un’azione, un valore numerico che indichi il “premio” per quanto fatto (alla stregua del biscotto che viene dato a un topolino capace di trovare l’uscita in un labirinto). Ad esempio: un premio positivo ogni volta che il braccio robotico afferra la palla; un premio negativo (o “punizione”) ogni volta che la palla viene fatta cadere per terra; nessun premio per altre azioni. Nel prossimo numero, vi racconterò i successi di questo approccio, ma anche divertenti risultati legati appunto nel comportamento emergente in queste macchine.
(continua…)
Autore: Marco Montali

Nell’ultimo numero della “città digitale”, abbiamo raccontato brevemente cosa sia il Sistema Pubblico di Identità Digitale (meglio noto con l’acronimo SPID) e come si possa ottenere la popria identità digitale con SPID. Per chi si fosse perso l’articolo: le istruzioni ufficiali sono disponibili al link www.spid.gov.it
Una volta ottenuto il proprio accesso SPID, cosa ce ne facciamo? L’idea è quella di fornire al cittadino una serie di servizi dell’amministrazione pubblica in forma digitale: senza dover recarsi fisicamente in un ufficio, senza code, ed integrando quanto più possibile i dati del cittadino stesso. “Amministrazione pubblica” è qui da intendersi in senso lato: si va da servizi offerti dai paesi dell’unione europea che hanno aderito all’iniziativa italiana, fino a servizi offerti dalle singole province. Rimanendo sul territorio nazionale, si va da la richiesta di finanziamenti per aziende e privati fino ai servizi INPS e INAIL, quelli dell’anagrafe, e quelli appunto delle amministrazioni locali.
A Bolzano, il portale web chiamato “myCIVIS”, raggiungibile all’indirizzo web my.civis.unibz.it, offre una vasta gamma di servizi a livello provinciale e dei singoli comuni: richiesta d’iscrizione online per le scuole primarie e gestione dei servizi mensa, dichiarazione DURP per redditi e patrimonio, portale provinciale dei pagamenti, solo per citare alcuni esempi.
Particolarmente interessante è il fatto che nuovi servizi possono essere facilmente aggiunti dall’ente pubblico, sfruttando appunto il fatto che la verifica dell’identità del cittadino viene gestita, in sicurezza e con garanzia di privacy, proprio da SPID stesso.
Si tratta, in conclusione, di un servizio che può inizialmente presentare un po’ di difficoltà nel comprendere come registrarsi e nel prendere confidenza su come utilizzare la propria identità digitale. Passato questo scoglio, però, si può davvero beneficiare del fatto che le nostre città stanno diventando, sempre di più, città digitali, permettendoci di effettuare operazioni anche molto complesse comodamente da casa.
Autore: Marco Montali

Nel 2013, il deputato Stefano Quintarelli ebbe un’idea pionieristica: quella di rendere più semplice l’accesso ai servizi pubblici utilizzando le tecnologie informatiche. L’idea era quella di superare l’intricata burocrazia del cartaceo e dei classici “mille uffici” da consultare per ottenere un servizio, permettendo ai cittadini di accedere a quello stesso servizio tramite internet. Tra i problemi più difficili da risolvere, ce n’era in particolare uno. Quando si va in un ufficio, la prima cosa da fare è mostrare la propria identità. Come rendere possibile questo nel mondo digitale, garantendo sicurezza e privacy? Dalla soluzione di questo problema è nato l’ormai famoso SPID – letteralmente “Sistema Pubblico di Identità Digitale”, attualmente riconosciuto come sistema di riconoscimento della propria identità valido in tutti i paesi membri della Comunità Europea. Per poter richiedere lo SPID, è necessario rivolgersi a enti accreditati capaci di fornire l’identità digitale, e quindi creare “l’alter ego” digitale del cittadino. Questi enti, chiamati “identity provider”, sono riconosciuti e vigilati da AgID, l’Agenzia per l’Italia Digitale, agenzia pubblica che opera sotto la vigilanza diretta del presidente del Consiglio dei ministri. Come si può evincere facilmente visitando il sito ufficiale di SPID (www.spid.gov.it), nove sono gli “identity providers” attualmente accreditati. Tali enti definiscono specifiche procedure per creare l’identità digitale di un cittadino. Queste procedure si basano principalmente sul riconoscimento del cittadino effettuato da una persona preposta, tramite tesserino del codice fiscale, carta di identità, e riconoscimento facciale – esattamente come accade di solito. Ciò può avvenire in presenza o, per vari enti, utilizzando la videocamera del proprio computer o cellulare. Una volta effettuato questo primo passaggio, è possibile accedere a tutti i servizi associati a SPID utilizzando la propria identità digitale. In base alla tipologia di servizio e alla corrispondente esigenza di sicurezza, ci sono tre diverse modalità per poter provare la propria identità, corrispondenti a tre livelli di sicurezza. Per i servizi di primo livello, al cittadino viene richiesta la classica coppia “nome utente” e “password”… con il vantaggio che questa stessa coppia può essere definita una volta per tutte, e poi utilizzata per accedere a tutti i servizi collegati a SPID. Per i servizi di secondo livello, oltre al nome utente e alla password viene anche richiesta una ulteriore password “usa e getta” (in inglese OTP – one-time password), che viene generata da una app specifica da installare sul proprio cellulare. Per i servizi di terzo livello, viene anche richiesto l’uso di una smartcard – modalità di autenticazione supportata solo da alcuni degli “identity provider” attualmente accreditati.
In pratica, SPID ci permette di ricorrere ad un’unica modalità di autenticazione per provare la nostra identità nel mondo digitale. Ma a quali servizi possiamo accedere a quel punto? Ne parleremo nel prossimo numero della “città digitale”.
continua…
Autore: Marco Montali

Nella faticosa bagarre legata al green pass, in molti hanno per
la prima volta avuto a che fare con un QR Code: un’immagine quadrata contenente quadratini neri e bianchi, che viene letta da dispositivi (come i cellulari equipaggiati di un’opportuna app) per decifrarne il contenuto. Ma da dove vengono questi QR code? E che cosa sono?
I QR Code nascono nel 1994 in Giappone: un’invenzione della DENSO Wave, divisione della DENSO Corporation, multinazionale produttrice di componenti per l’industria automobilistica. Il modo più semplice per capire cosa sia un QR Code è di pensarlo come una forma più sofisticate di “codice a barre”.
I codici a barre codificano in modo compatto informazioni utili, come le principali informazioni di un prodotto o di un biglietto del treno, i dati di una persona, l’indirizzo web di un’azienda, ecc. Si prestano ad essere stampati e applicati su contenitori e manifesti pubblicitari, oppure ad essere mostrati in un cellulare, grazie alla loro semplicità e ridotte dimensioni.
I codici a barre codificano informazione lungo una singola dimensione nello spazio: guardandoli in senso perpendicolare alle linee, si può immaginare che una linea nera rappresenti un “1”, e una linea bianca rappresenti uno “0”. Questo pone dei limiti su quanta informazione si può in effetti codificare in un codice a barre… si narra che fin dagli anni ‘60 in Giappone ci fosse un dibattito aperto su come superare questo limite, per poter aumentare l’informazione da associare ai prodotti nei supermercati.
Il QR Code affronta questo problema codificando l’informazione lungo due dimensioni: non più linee, bensì quadratini, dando quindi “significato” sia alla larghezza che all’altezza del codice. Per poter leggere il contenuto di un QR Code, così come di un codice a barre, serve un dispositivo (o un software associato a una fotocamera) che sia capace di leggere l’informazione ivi nascosta, e decifrarlo. Questo ci porta ad un problema centrale, ovvero: quanto è facile per un lettore leggere il codice e decifrarlo? Si tratta di un problema molto complesso, perché il codice potrebbe essere inquadrato con qualunque orientamento. Il QR Code risolve questo problema introducendo degli “elementi di controllo” che permettono di ricostruire molto velocemente come riorientare l’immagine per poterla poi decifrare. è proprio da questa “velocità di decodifica” che viene il nome stesso: QR sta per “Quick Response” – “risposta veloce”.
I cellulari di ultima generazione sono capaci di decifrare i QR code semplicemente usando la fotocamera del telefono. Per creare dei QR code che nascondano un’informazione voluta servono invece delle app dedicate – ce ne sono moltissime disponibili per iOS e Android.
Autore: Marco Montali

Ha fatto scalpore, a febbraio di quest’anno, la notizia, apparsa sulla BBC, che un numero impressionante di e-mail che riceviamo contiene un vero e proprio “trucco da prestigiatore” per tracciare informazioni sul ricevente. Per chi è interessato a leggere la notizia originale, basta cercare sul web il titolo “Spy pixels in emails have become endemic”. Il titolo stesso indica che questo trucco si basa sugli “spy” pixel.
Per spiegarvi come funziona, devo brevemente raccontarvi che quando navighiamo sul web, le pagine che vediamo vengono caricate sulla base di informazioni che otteniamo da computer “lontani”. Immaginate che con il mio cellulare (chiamiamolo C) io voglia vedere su web la foto di un hotel che mi piace. Quella foto è memorizzata nel computer dell’hotel (chiamiamolo H) collegato in rete (non possiamo qua approfondire come fa C a trovare H – immaginiamo che lo conosca già). Per ottenere l’immagine da H, C avvia un “protocollo di scambio informazioni”… immaginatelo proprio come due persone che si parlano: C si presenta, H risponde, poi C chiede di avere la foto, H la cerca e la spedisce a C (o meglio, spedisce i bit che permetteranno a C di ricomporre l’immagine).
Adesso immaginatevi lo stesso tipo di interazione, ma avviato in modo “nascosto”. Questo è quello che succede con quei famigerati “spy pixel” all’interno di una e-mail. Gli spy pixel altro non sono che minuscole immagini trasparenti, quindi invisibili all’occhio umano, che vengono inserite all’interno di una e-mail. In realtà, nell’e-mail viene inserito il fatto che quelle piccoli immaginette andranno richieste via internet a un computer lontano (chiamiamolo Z, il computer dell’azienda che ci ha mandato l’e-mail, esattamente come l’immagine dell’hotel memorizzata da H). A quel punto, appena apriamo l’e-mail, viene messo in moto, senza che ce ne accorgiamo, lo stesso protocollo che abbiamo descritto sopra per C e H, solo che questa volta il risultato è che C mostrerà un’immagine trasparente di cui la persona che sta leggendo l’e-mail non si accorgerà. Il fatto è che mentre C e Z si parlano, Z può memorizzare informazioni su C, come ad esempio le informazioni su dove C è localizzato, su quando l’e-mail è stata aperta, e altro. Questo è solo uno dei tanti esempi di come, ad oggi, produciamo continuamente dati senza che ce ne accorgiamo.
Autore: Marco Montali